paddle OCR 的文字识别过程
Posted on 2025-10-05 20:00 in AI
PaddleOCR 是百度开源的一个非常优秀的 OCR 模型 + pipeline,基于百度自己的 paddlepaddle 框架,虽然文档写得让人非常难以上手,而且都是基于百度自己的框架实现的。
下面以最常见的一个普通的 OCR 过程为例子,参考 RapidOCR 的代码,解读一下 OCR 的过程,虽然跟现在流行的大模型差别比较大,但是基本原理应该是一样的。
下面使用 PP-OCRv5 的模型。
paddlepaddle 的模型可以转换成 onnx 模型,然后通过 onnxruntime 来运行,虽然用的 lib 不一样,但是原理是一样的
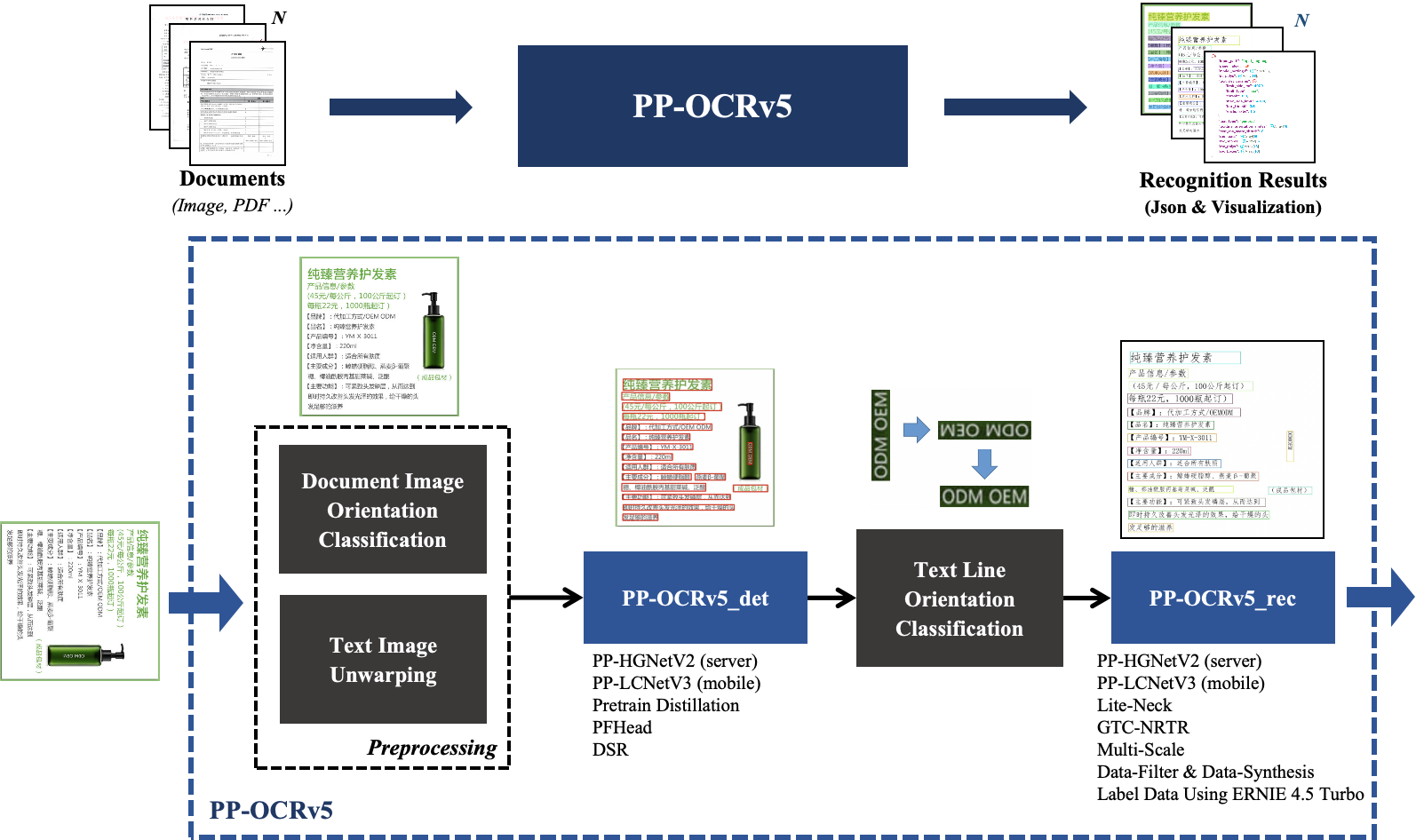
如图,有两个可选的逻辑 1. 文档方向分类模型,含有四个类别,即0度,90度,180度,270度 2. 文本图像校正模型,针对倾斜的图像,把文本旋转到正确的角度
文本检测模块
输入是一个图片,需要向量化
输出的也是向量,可以转换成 BBOX 四个点
flowchart TD
A["图片"] --> B["HWC
Height
Width
Color(RGB)"]
B --> C["resize
最长边960
边长是32的倍数"]
C --> D["Normalize
归一化/255
减去均值
除以标准差"]
D --> E["向量NCHW
NCHW"]
E --> F["模型
PP-OCRv5_mobile_det"]
F --> G["输出向量
N,1,H,W"]
G --> H["二值化
使用thresh阈值(默认0.3)
将概率图转换为二值掩码"]
H --> I["轮廓提取
使用OpenCV的cv2.findContours
提取文本区域轮廓"]
I --> J["最小外接矩形计算
对每个轮廓使用minAreaRect
计算最小外接矩形"]
J --> K["过滤
计算矩形区域平均分数
过滤低置信度/小尺寸框"]
K --> L["扩展
检测框进行扩展
确保包含完整文本"]
L --> M["坐标映射
映射回原始图像尺寸
并裁剪边界"]
文本识别模块
先用上面的 BBOX,把图片切分成一小块一小块,然后再针对每张或者一个批次,进行识别
输出是向量,能对应到词表的某个词
flowchart TD
A[图片] --> B[按照矩形坐标裁剪图片]
B --> C[几个图片做一批次 NCHW]
C --> D[模型 PP-OCRv5_mobile_rec]
D --> E[向量 N, 文本长度, 字符集长度]
E --> F[取概率最高的字符]
F --> G[文本]
subgraph 批次处理说明
C -.-> H[注释:计算批次内的最大宽高比,用于统一 resize,
然后 padding,归一化]
end
style H fill:#fff3cd,stroke:#856404,stroke-dasharray: 5 5
表格识别模块
SLANet_plus 表格识别模型,识别出单元格,然后跟 OCR 识别的坐标信息结合起来就可以实现表格识别,最后结果为 html 表格
graph TD
Image[图片] --> Preprocess["图片预处理
1. resize 最长边 488
2. 归一化/255
减去均值
除以标准差
3. 填充到 488x488"]
Preprocess --> Model[模型 SLANet_plus]
Model --> Output1[输出 单元格矩形框序列]
Model --> Output2[输出 html标签序列]
Output1 --> OCR[跟 OCR 的矩形框
计算最大交集]
OCR --> Content[每个单元格里的
文字内容]
Content --> HTML[html 表格]
Output2 --> HTML